Real-World Benchmarks for AI Agents: The xbench Evaluation Framework
As AI models and agents move from static benchmarks into real‑world workflows, the way we evaluate them needs to change. Traditional benchmarks still matter, but they often fall short when it comes to practical questions: Can an AI system operate reliably in messy, evolving environments? Can it deliver real business value? Can it function as part of a production process?
xbench was built to address this gap. It’s a collaborative, continuously evolving evaluation platform that measures both fundamental intelligence breakthroughs and real‑world professional performance. By bringing together model developers, agent builders, industry practitioners, and researchers, we create benchmarks that are demanding, credible, and grounded in how AI is actually used. Our framework combines live, real‑world evaluations with carefully curated datasets so results remain meaningful as models, tools, and use cases evolve.
At the core of xbench is a dual‑track evaluation system spanning AGI Tracking and Profession‑Aligned benchmarks. Together, they provide a clear path from early capability breakthroughs to production‑level readiness, helping us identify when new intelligence emerges, understand how it translates into real workflows, and anticipate when AI applications are approaching true tech‑market fit.
Dynamic Real-World Evaluations (Live Evaluations for Agents)
At a practical level, this dual‑track design shows up as two complementary evaluation paths: xbench‑AGI Tracking and xbench‑Profession‑Aligned. AGI Tracking serves as the foundation, while Profession‑Aligned evaluations build on it by testing whether those capabilities hold up in real production scenarios.
AGI Tracking evaluations focus on identifying genuine “0‑to‑1” breakthroughs in specific capabilities. These tests are intentionally difficult and carefully designed to probe the limits of intelligence itself, rather than a model’s ability to recall training data. When a capability clears this bar, it becomes possible to apply it to more complex, real‑world workflows, and that’s when it’s ready to move into Profession‑Aligned evaluation.
Profession‑Aligned evaluations shift the focus to real work. Here, we treat an AI Agent less like a model and more like a digital employee embedded in an actual business process. What matters isn’t abstract intelligence, but whether the Agent can deliver results and measurable business value. We don’t constrain how the Agent gets there or which model it uses; we evaluate outcomes. Starting from real productivity needs, we define tasks drawn from specific industries and look for AI solutions—even in cases where no fully formed product exists yet.
Take Marketing and Recruiting as examples.
By tracking performance in our xbench DeepSearch (AGI track) evaluations, we saw that the AI search capabilities was improving rapidly. That made workflows like resume screening and candidate fit analysis, or identifying and evaluating influencers for marketing campaigns, feel increasingly achievable. Based on these signals, we launched xbench-Profession-Recruitment and xbench-Profession-Marketing, both designed to mirror real business processes and to anticipate when these applications might reach Tech‑Market Fit.
Looking ahead, as AI capabilities expand into multimodal understanding and generation, even more complex tasks come into scope, such as creating and placing marketing creatives. In recruiting, the bar is higher still. Beyond sourcing and evaluation, senior recruiters spend much of their time on long‑term relationship management, compensation negotiation, and closing candidates. Supporting these steps requires capabilities like long‑term memory, strategic reasoning, and nuanced decision‑making.
These areas — long‑term memory, multi‑agent collaboration and negotiation, and problem discovery — are the next frontiers we’re watching closely. As breakthroughs emerge, we’ll continue to expand and refine our Profession‑Aligned evaluation sets to reflect what’s becoming possible in real‑world work.
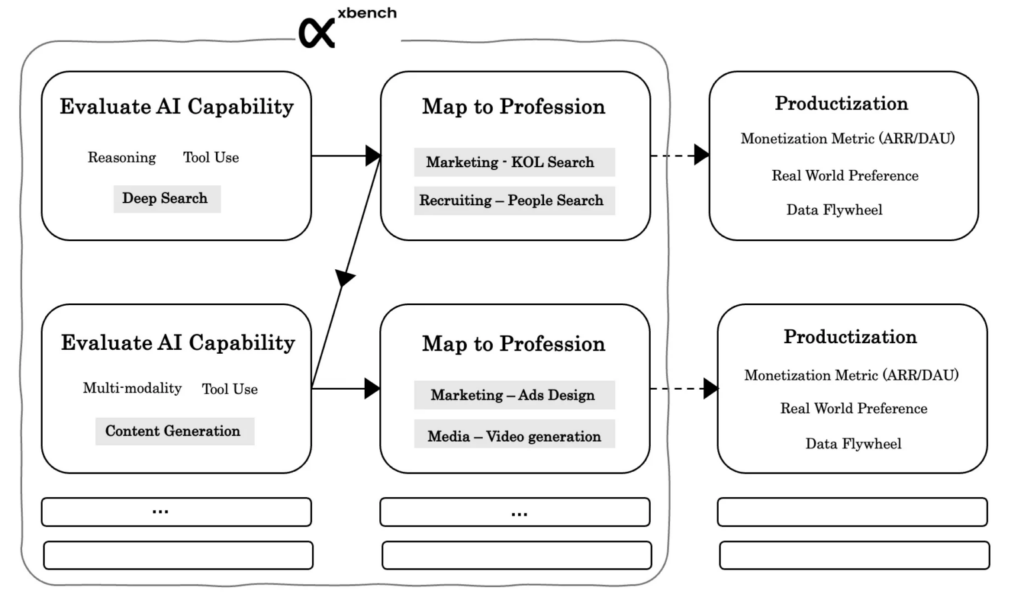
Evaluation Centered on Core AI Capabilities (AGI Tracking)
Between 2023 and 2024, large models made rapid progress across a range of core abilities—knowledge, multimodal understanding, memory, instruction‑following, and reasoning. Together, these breakthroughs dramatically expanded what AI Agents could do in practice. At the same time, important gaps remain. Capabilities like long‑term memory, reliability and truthfulness, problem discovery, multi‑agent collaboration, and strategic decision‑making are still far from solved.
AGI Tracking is designed to focus squarely on these open problems. We build and maintain evaluation sets that target these core capabilities directly, with the goal of identifying when real breakthroughs happen—not just incremental improvements.
Many of these capabilities have already been studied extensively in academia, and there is no shortage of thoughtful evaluation designs. The challenge is that most of these benchmarks are released once and then left untouched. As models evolve, the evaluations quickly fall out of date. With xbench, we aim to extend the spirit of open evaluation by turning these ideas into live, continuously updated benchmarks, supported by independent third‑party testing. Depending on the task, this includes both black‑box and white‑box evaluations.
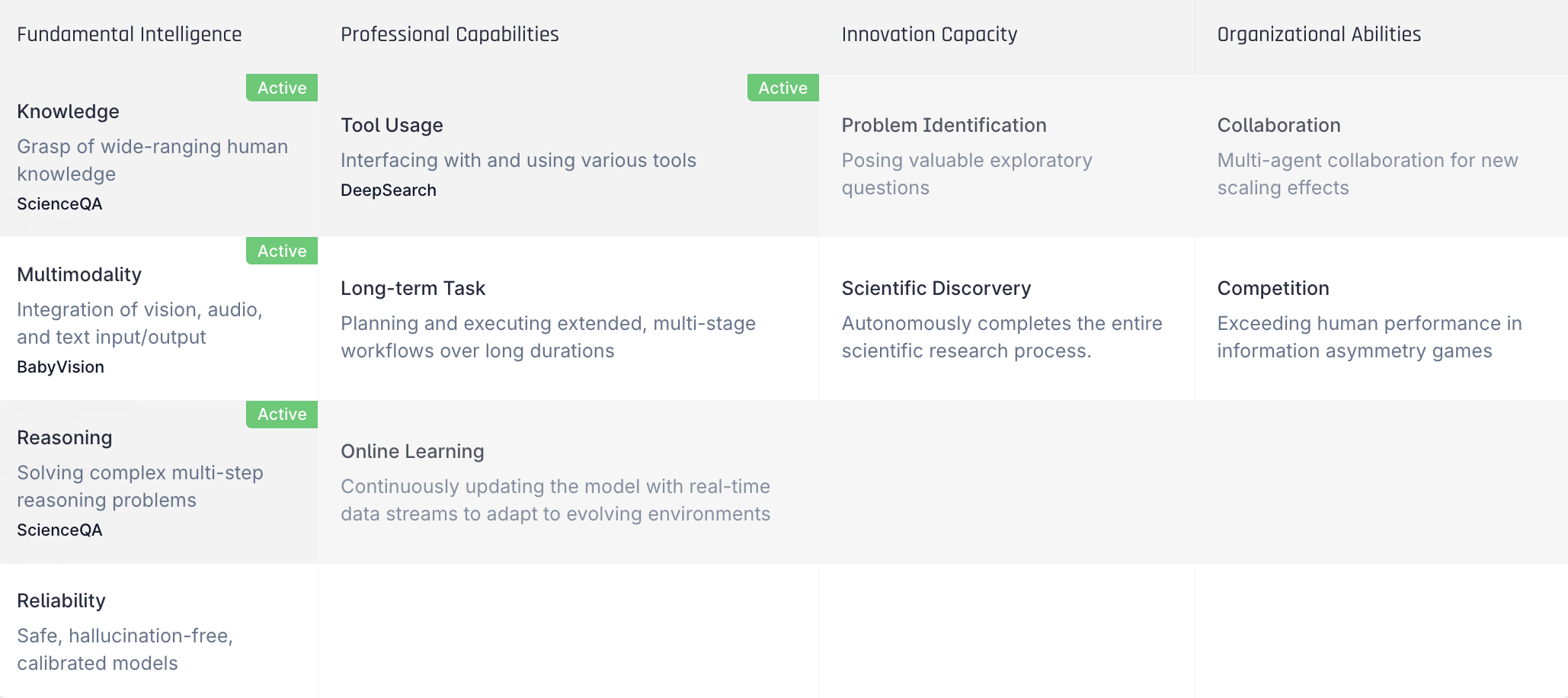
To organize this effort, we break an Agent’s abilities into four broad tiers: fundamental intelligence, professional proficiency, creative ability, and organizational ability. For each tier, we identify the capabilities that matter most on the path toward AGI. Progress across these tiers isn’t always linear—an Agent might show sophisticated organizational behavior while still struggling with basic reliability. That’s why our evaluations are designed to track multiple dimensions in parallel, rather than assuming a single, orderly progression.
In our first public release, xbench‑ScienceQA and xbench‑DeepSearch focus on the “Knowledge” and “Tool Use” capability categories, respectively. Each evaluates these abilities through concrete, task‑level tests. Over time, we’ll continue adding new evaluations across other core capability areas and use them to track how today’s AI systems—and the ones that follow—actually improve.
xbench-ScienceQA – Evaluating Fundamental Intelligence (Knowledge)
xbench‑ScienceQA is designed to test graduate‑level academic knowledge and reasoning. The questions span multiple disciplines and are intentionally challenging, with clear, unambiguous answers that can’t be solved by a quick search. The goal is to assess genuine understanding and reasoning ability, not lookup skills.
Existing benchmarks like GPQA and SuperGPQA have played an important role in advancing this area, but as one‑time releases, they’re difficult to keep fresh over time. With xbench‑ScienceQA, we take a different approach. The question set is updated quarterly, and we report model performance on a monthly basis to ensure results remain meaningful as models evolve.
Questions are contributed by PhD students from leading universities and experienced industry practitioners. We put each item through multiple checks — including difficulty testing with LLMs, search‑engine validation, and peer review — to ensure fairness, clarity, and strong differentiation across models.
xbench-DeepSearch – Evaluating Professional Productivity (Tool Use)
Deep search is one of the most important — and hardest to evaluate — capabilities on the path toward AGI. It requires an agent to plan its approach, gather information, reason over what it finds, and synthesize a coherent result. In practice, this end‑to‑end ability is far more demanding than simple information retrieval.
Existing benchmarks tend to capture only part of this picture. Fact‑based tests like SimpleQA are useful for measuring retrieval, but they don’t assess planning or multi‑step reasoning. On the other hand, advanced reasoning benchmarks such as HLE or AIM‑E probe cognitive depth but say less about an agent’s ability to search, plan, and integrate external information.
To close this gap, we developed and open-sourced the xbench-DeepSearch benchmark with a few core design principles:
- It’s tailored to the Chinese internet environment, reducing dependence on any single source.
- It’s intentionally challenging, requiring agents to plan, search, reason, and summarize in a fully integrated way.
- All questions are written and cross‑validated by humans, ensuring novelty, correctness, and uniquely identifiable answers.
- The benchmark evolves over time: we publish monthly performance updates and refresh the question set every quarter.
Looking ahead, we expect continued progress in both foundational intelligence and real‑world productivity. In upcoming evaluations, we’re paying close attention to questions like:
- Multimodal reasoning & tool use: Can models reason over images or video and produce outputs — such as marketing videos — that meet commercial standards?
- Reliability of tool-using Agents: As protocols like MCP (Model-Context Protocol) become more widely adopted, do they introduce new reliability or trust issues?
- Adaptability of GUI Agents: Can agents operate software interfaces that change frequently or that they’ve never seen before?
Evaluation Centered on Professional Work (Profession-Aligned)
If we want AI evaluations to matter in the real world, they need to reflect real work. That idea sits at the core of our Profession‑Aligned approach.
Most benchmarks today are capability‑centric. They aim to cover a wide range of tasks and domains to guide general model development, and they’ve played an important role in tracking overall progress. But when AI agents move into production, broad generality matters less than performance in a specific role or industry. In those settings, generic benchmark scores quickly lose their usefulness.
We’ve already seen how domain‑specific evaluations in areas like coding, customer service, and medicine have driven faster technical progress and real product adoption. We expect this pattern to continue, with profession‑centered benchmarks becoming a much larger part of mainstream AI evaluation as more industries recognize the need for assessments that reflect their own workflows.
Designing these evaluations starts with human experts. We look closely at how professionals in a given field actually work — their day‑to‑day workflows, decision points, and constraints — and then build tasks, environments, and evaluation criteria around that reality. The goal is to measure not just what an AI can do, but whether it can meaningfully contribute in a real professional setting.
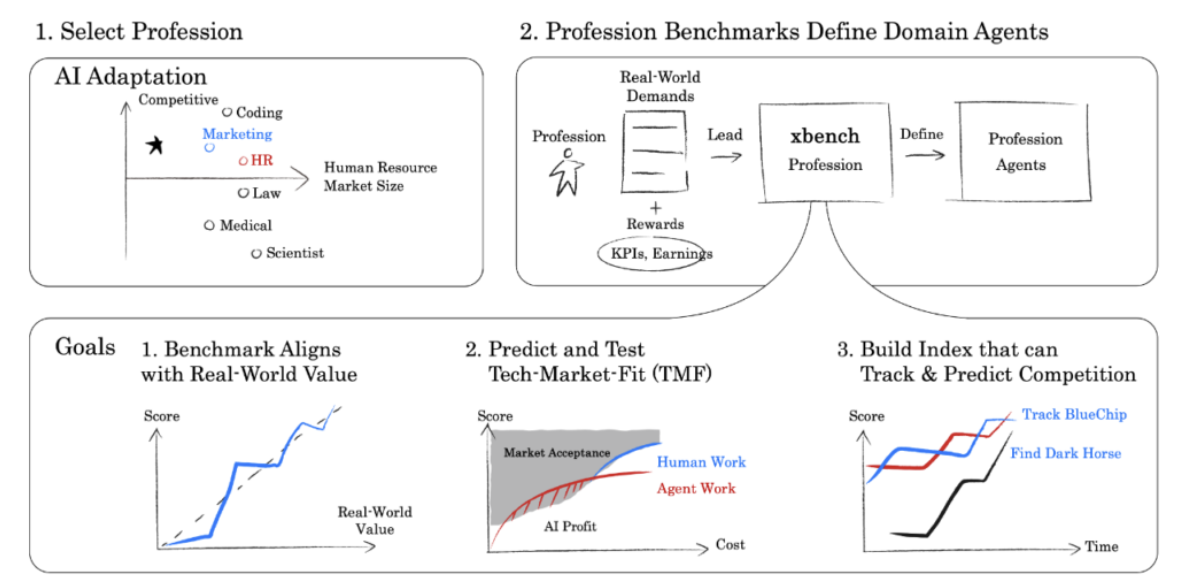
xbench’s Profession-Aligned benchmarks follow three core principles:
- Demand-defined evaluations: For each profession, we begin by mapping out the full business workflow and its major task categories. From there, we focus on tasks that can be evaluated objectively. For parts of the job that aren’t yet easy to measure, we simulate or translate them into formats that can be evaluated reliably.
- Live task collection over time: Rather than creating a fixed set of “exam questions” upfront, we collect evaluation tasks gradually from the day‑to‑day work of domain experts. As workflows evolve, we continuously add new tasks drawn from real business settings, so the benchmark stays closely aligned with current practice.
- Value-driven targets: For each task, we estimate its economic value by looking at how long it takes a human expert to complete and benchmarking against industry compensation. Each task is given a preset tech‑market‑fit (TMF) target. Once an AI Agent meets that performance‑to‑cost threshold, we stop increasing the task’s difficulty. The goal isn’t to push difficulty endlessly, but to define the point at which performance is good enough to be commercially viable.
As a concrete example, we designed xbench-Profession-Recruitment by by starting with the work of experienced recruiters. We partnered with leading headhunting firms to break down how recruiters actually spend their time across different tasks and to assess the importance of each one. This produced a structured view of the domain’s workflows. We then aligned each task with its economic value and analyzed which ones are both feasible and measurable with today’s AI technology.
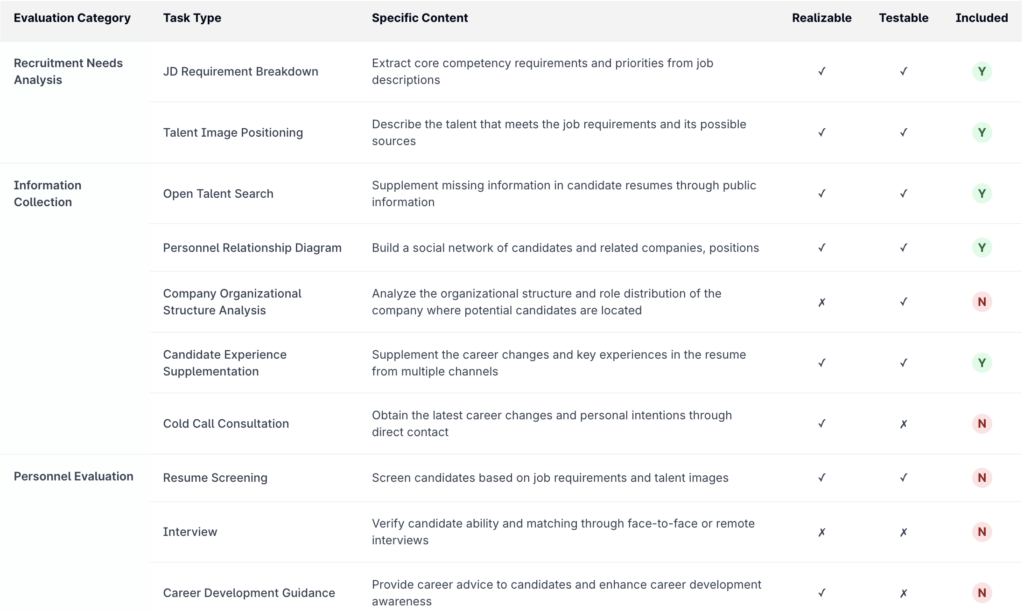
For each task, we look at whether it can be evaluated reliably and whether it’s feasible with today’s AI. The first release of xbench‑Profession‑Recruitment covers a range of practical recruiting tasks, including understanding job requirements, identifying candidate personas, filling in gaps in a candidate’s experience, making sense of social and professional connections, and searching publicly available talent profiles.
Evergreen Evaluation (Continuous Benchmarking)
Every evaluation task and every product has a life cycle. One long‑standing issue with static benchmarks is question leakage: once questions are fixed, models eventually learn them. Recent efforts like LiveBench and LiveCode, which rely on continuously refreshed question pools, have helped reduce leakage and overfitting. But evaluating AI Agents introduces a new set of challenges.
The first is that Agent products themselves change over time. They evolve quickly, adding new capabilities while older versions are retired. This means that while we can compare different products within the same evaluation round, it’s much harder to compare a single product’s performance across time when both the product and the evaluation set keep changing.
The second challenge comes from the environment Agents operate in. Many tasks require interacting with external tools or live internet resources. Even if the evaluation question stays the same, changes in available information or tools can lead to different outcomes at different points in time.
Live evaluations therefore produce results that look like an incomplete matrix: some products appear in some rounds but not others, and tasks change as the environment evolves. These results are useful for ranking products within a single round, but they don’t tell us how an individual Agent’s underlying capability improves over time. That raises a key question: how do we track continuous capability growth when both the models and the benchmarks are moving targets?
Tracking capability over time with IRT
We approach this problem statistically. Instead of treating each evaluation round in isolation, we model the incomplete score matrix over time to estimate each Agent version’s underlying capability.
To do this, we apply Item Response Theory (IRT), to estimate an Agent’s capability in a way that is robust to changing test items. In IRT, an agent’s ability θ, a question’s difficulty b, and a question’s discrimination factor a are modeled such that the probability of a correct response is:
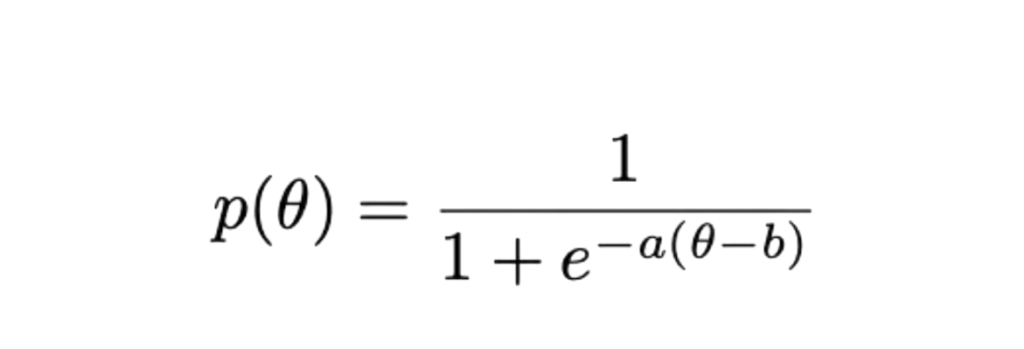
In this model, the probability p of solving a question falls between 0 and 1. A higher difficulty parameter b lowers the probability of success, while a higher ability θ raises it. Questions with a larger discrimination a have a more gradual score curve as ability θ increases, meaning such questions differentiate performance across a wider range of ability levels.
We validated this approach using dynamically updated results from the OpenCompass project to validate the IRT approach. Since February 2024, OpenCompass has refreshed its question set every 1–3 months while continuing to publish evaluation results. On the raw leaderboard, models can be ranked at each point in time, but scores from different rounds aren’t directly comparable because the questions change.
In the figure below, we plotted the scores of various models at each evaluation time; models from the same family are connected by lines of the same color. The raw leaderboard is excellent for showing models’ rankings at each evaluation point, but because questions change, a model’s scores at different times are not directly comparable.
However, when we use IRT to estimate an ability score for each model at each point in time, we can clearly see the continuous improvement trends in model capabilities. For example, we observed a rapid jump in ability for Google’s Gemini model after October 2024, and two noticeable performance boosts corresponding to the releases of DeepSeek versions r1 and v2.
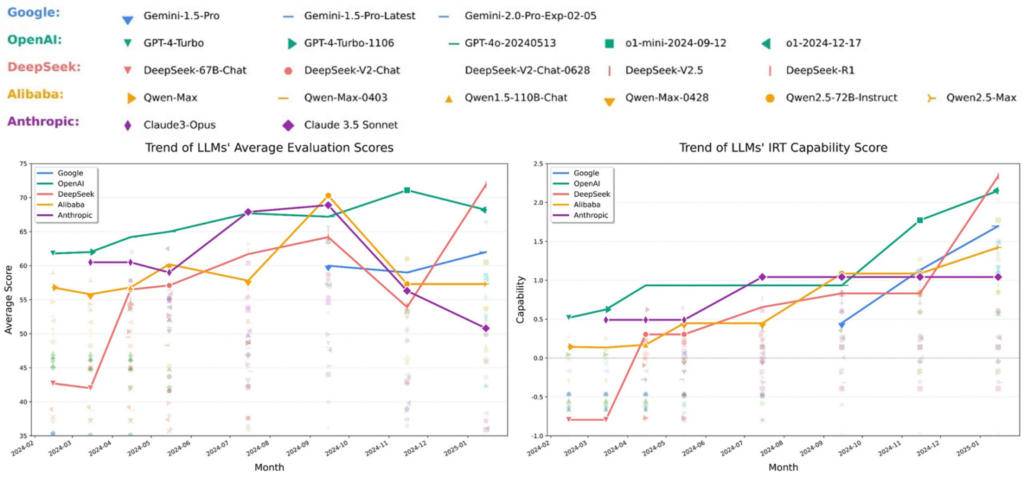
Going forward, xbench will report IRT‑based capability scores for Agent products across all evaluation sets. This lets us track not just who’s ahead at a given moment, but how quickly each product is improving — and when genuine breakthroughs occur beyond simple ranking changes.
Evaluating an Agent’s Tech-Market Fit (TMF)
Capability alone isn’t enough for real‑world deployment. Cost matters just as much.
In practice, Agent performance can often be improved through inference scaling — using more computation at runtime. This might mean longer chains of reasoning, more iterative refinement, or additional tool calls. While these techniques can boost performance, they also increase latency and cost.
For real‑world applications, what matters is the return on that extra compute. There’s always a trade‑off between performance, cost, and speed, and the optimal point depends on the task. Inspired by the ARC‑AGI framework, we plan to visualize this trade‑off for each xbench evaluation set using performance‑cost curves. These include a demand curve, a reference curve for human performance, and a supply curve representing the best available Agent systems.
On a score‑versus‑cost chart, the upper‑left region represents what the market will accept: strong performance at a reasonable cost. The bottom‑right region represents what’s technically possible but too expensive to deploy at scale. The cost of human labor effectively sets one boundary of the market‑acceptable zone.
Before an application reaches tech‑market fit, these regions don’t overlap. After TMF, they do—and that overlapping area represents the real economic value AI creates.
Once an Agent reaches TMF, the role of human labor begins to shift. AI takes on more routine, repeatable work, while humans focus on frontier tasks and areas where AI still falls short. Because AI and human labor have very different cost and scarcity profiles, markets naturally adjust how they value each.
We see most professional domains moving through three broad stages:
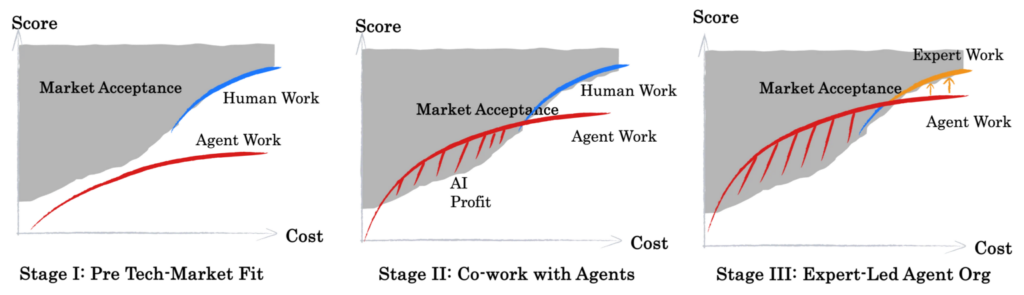
- Before TMF (No Fit): Technically achievable performance doesn’t meet market requirements. Agents are experimental tools rather than viable products, and their impact on real work is limited.
- Human-AI Collaboration: Technically feasible and market‑acceptable performance begin to overlap. AI delivers incremental value — by lowering costs, handling repetitive tasks, and boosting productivity — while complex, high‑skill work remains human‑led.
- Specialized AI Agents: Domain experts take the lead in building evaluation systems and guiding Agent development. Human effort shifts from producing outcomes directly to defining standards, training Agents, and shaping workflows. At this stage, AI Agents become true specialists within their domains.
The transition from Stage 1 to Stage 2 is driven by AI technology breakthroughs and the scaling of compute and data. The transition from Stage 2 to Stage 3 depends on experts who deeply understand the vertical domain’s needs, standards, and accumulated experience. It’s worth noting that in some fields, AI may even reshape workflows entirely, creating new ways of meeting demand.
Ultimately, AI is likely to bring about shifts in value and changes in the labor structure. We believe that thanks to more efficient productivity and new business models, overall societal welfare will improve – even as roles and tasks evolve.