Introducing xbench: the Evergreen Benchmark for AI Agents
xbench is HSG’s evergreen benchmark for AI agents. Dual-track evaluations measure capability ceilings and real-world utility, starting with ScienceQA and DeepSearch.
As foundation models advance rapidly and AI Agents enter scaled deployment, widely used AI benchmarks are encountering an increasingly acute problem: it is becoming increasingly difficult to accurately reflect the true capabilities of AI systems. Building a more scientific, enduring, and reliable evaluation system for AI’s objective abilities has become an urgent priority to guide breakthroughs in AI technology and iterations of AI products.
To address this, HSG has officially launched a new AI benchmarking tool called xbench, alongside the release of a research paper titled “xbench: Tracking Agents Productivity, Scaling with Profession-Aligned Real-World Evaluations.”
What is xbench?
xbench is tool designed to evaluate and push AI systems to extend their capability ceilings and technological frontiers, while also quantifying the practical utility value of AI systems in real-world scenarios. Notably, xbench adopts an “evergreen” evaluation mechanism to continuously capture key breakthroughs in AI Agent products over time.
xBench Features
Dual-Track Evaluation – Theoretical vs. Practical
xbench employs a dual-track evaluation system with multi-dimensional test datasets, aiming to simultaneously track a model’s theoretical capability limits and an Agent’s actual real-world utility. This system innovatively divides evaluation tasks along two complementary main lines:
- Assessing an AI system’s capability ceiling and technological frontier
- Quantifying the AI system’s utility value in real scenarios (its Utility Value)
The latter track dynamically aligns with real-world application needs by using actual workflows and specific professional roles to construct evaluation criteria that have clear business value in each vertical domain.
Evergreen Evaluation Mechanism
xbench uses an “evergreen” evaluation approach by continuously maintaining and dynamically updating its test content to ensure timeliness and relevance. We will regularly evaluate mainstream AI Agent products, track the evolution of model capabilities, and capture the key breakthroughs during Agent product iterations – thereby predicting the next tech-market fit (TMF) for Agent applications.
As an independent third party, we are committed to designing a fair evaluation environment for each product category and to providing objective, reproducible evaluation results.
Core Benchmark Suites
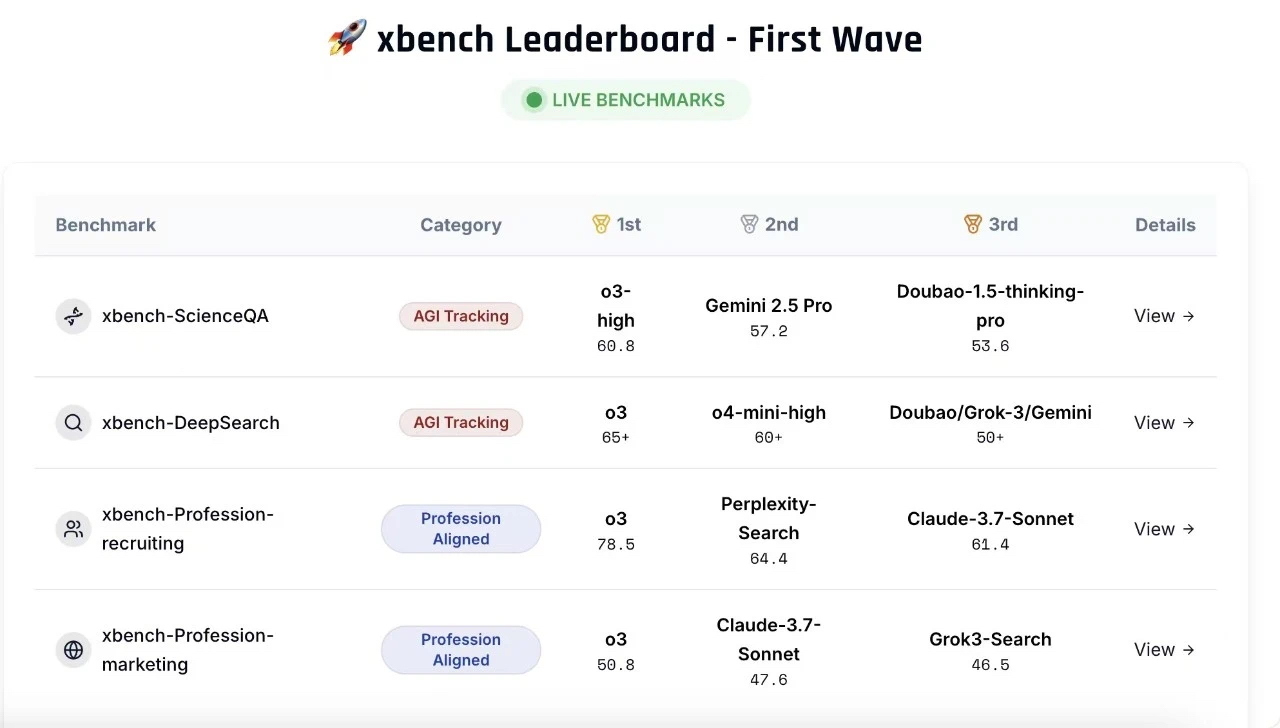
The first release of xbench includes two core evaluation sets: a Scientific Q&A Evaluation Set (xbench-ScienceQA) and a Chinese Internet Deep Search Evaluation Set (xbench-DeepSearch). We have also conducted a comprehensive ranking of the major products in these areas. In parallel, we propose a methodology for evaluating vertical-domain Agents and have built evaluation frameworks for Agent applications in the Recruitment (xbench-Profession-Recruiting) and Marketing (xbench-Profession-Marketing) fields. The evaluation results and methodology can be viewed in real time on the xbench website.
When will xbench go live?
For more than two years, xbench has been used internally at HSG to track and evaluate foundation model capabilities. Today, we’re making it public and contributing it to the broader AI community.
Whether you’re a foundation model or Agent developer, an expert or enterprise in a related field, or a researcher with a deep interest in AI evaluation, we welcome you to join us as part of the xbench effort.
Why Is a New AI Agent Evaluation System Needed Now?
After the debut of ChatGPT in 2022, HSG began conducting monthly evaluations and internal briefings on the progress of AGI and mainstream models. In March 2023, we started constructing the first batch of private question sets for xbench. These initial test questions were mostly simple chatbot Q&As and logical reasoning challenges, for example:
- “What is the square root of a banana?”
- “Jane Doe aspires to become the most successful investor. After much effort, she finally succeeds. What proverb best describes this situation?”
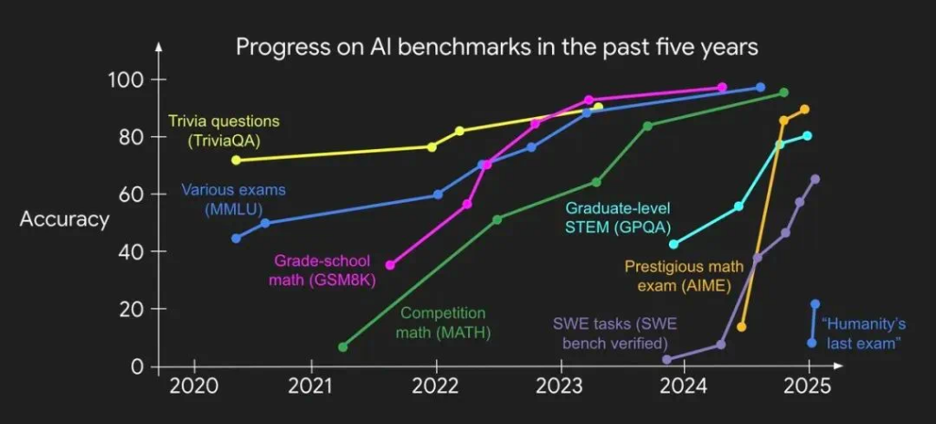
We witnessed mainstream models improve their scores from about 20–30% to around 90–100% over the span of 18 months on this first question set. By October 2024, we performed a second, large-scale update of the xbench question bank, replacing all the questions on which models had achieved perfect scores. The new questions were more complex, focusing on harder chatbot queries and reasoning, as well as basic tool-use abilities (e.g., calling external APIs or tools). For example:
- “Let f(x) be an odd function and g(x) be an even function. Is f(f(g(f(g(f(x))))))f(f(g(f(g(f(x)))))) odd, even, or neither?”
- “Q: In the /nt directory, merge all files matching the pattern ‘result_*.txt’ in ascending numeric order into one file named ‘results_total.txt’.”
Again, we saw significant progress – this time much faster. In only about six months, mainstream models reached saturation on our second-round question set and quickly achieved near-perfect scores.
Pushing the AI Evaluation Envelope
By March 2025, we began a third upgrade to the xbench question bank. However, this time we paused to reevaluate our approach – namely, two core issues:
1. The relationship between model capability and real-world utility
What is the point of continuously introducing ever-harder questions? Are we falling into a pattern of habitual thinking? Is the real economic value of AI deployments truly correlated with an AI’s ability to solve extremely difficult problems?
For example, coding work has very high utility value and AI has made remarkably rapid progress in that domain, whereas a task like “moving bricks at a construction site” is nearly impossible for AI to perform. In other words, not every hard task is economically valuable, and not every valuable task requires solving academic riddles.
2. Comparing capabilities over time
Each time we change the xbench question set, we lose continuity in tracking AI capability progress over time. With each new set of questions, the model versions have also changed, so we cannot directly compare a single model’s ability across different time points. When evaluating startups, we love to look at the “growth curve” of the founders, but in evaluating AI capabilities, we found that constantly updating the test set prevented effective judgment of a model’s improvement trajectory.
To address the above two core issues, we saw an urgent need to build a new evaluation platform focusing on two key aspects:
A. Breaking out of conventional thinking:
We need to develop novel task settings and evaluation methods that prioritize practical utility in the real world. For example, consider the evolution of the “search” capability for AI: Single-turn QA → Web Search → Deep Search (multi-step reasoning) → Deeper Search (multi-hop or chained reasoning).
If we step out of the inertia of a purely research-centric perspective and shift to a market and business perspective, the diversity of tasks and environments explodes. A “search” evaluation question then transforms into rich, domain-specific scenarios. For instance, in a Marketing context (KOL/influencer search):
- A smart projector brand plans to run a content campaign in the Middle East market targeting tech-savvy users under 35 who live on their own, primarily reached via lifestyle bloggers. The AI Agent needs to: (1) identify high-quality content creators across Chinese and English platforms and determine whether their content style aligns with “home entertainment + smart home”; (2) predict differences in click-through rates between regions (e.g., Dubai vs. Riyadh); (3) assist in producing a combined recommendation of creators.
Similarly, in a Recruiting context (talent search):
- A top VC-backed AI startup is seeking a lead AI engineer who has strong open-source project experience, is familiar with transformer architecture, and has interned or collaborated at FAIR or DeepMind. The ideal candidates may not be active on job boards; much of their information is scattered across GitHub, arXiv, X (formerly Twitter), and online community forums.
The AI Agent needs to: (1) perform cross-platform search and information aggregation; (2) reconstruct each candidate’s background (education, projects, internships); (3) automatically score the technical fit; (4) generate a draft for a cold outreach email. (Manually, this task might typically require one senior headhunter and one technical researcher over a week.)
These examples illustrate that in the “second half” of AI evaluation, we need not only increasingly difficult AI capability benchmarks for skills like Search, but also an array of utility-driven tasks aligned with real expert workflows. The former (capability evals) test the theoretical skill boundaries and yield quantitative scores, whereas the latter focus on practical task diversity, business KPIs (e.g., conversion rate, closing rate), and direct economic value.
To this end, we’re introducing the concept of “Profession Aligned” benchmarks. We believe that upcoming evaluations will diverge into two paths: AGI Tracking and Profession-Aligned evaluations. AI systems will face assessments of their utility in ever more complex, realistic environments, using dynamic task sets gathered from real business workflows – not just increasingly harder IQ test questions.
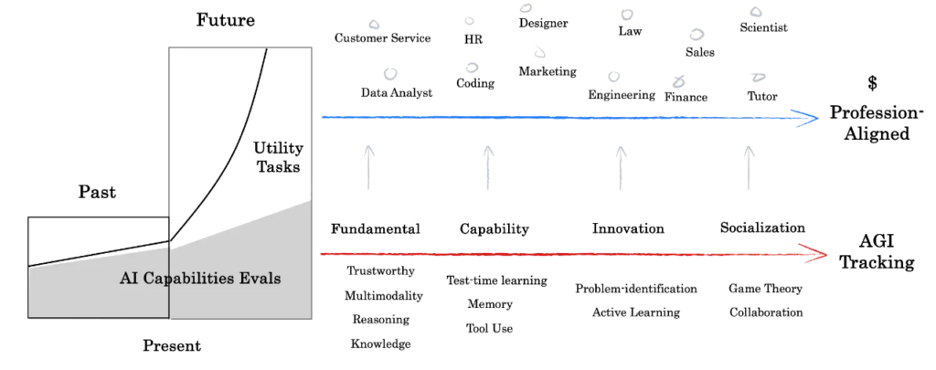
B. Establishing an “Evergreen” evaluation system:
Once a static evaluation set is released publicly, questions inevitably leak, leading to model overfitting and quickly rendering the benchmark obsolete. We plan to maintain a dynamically updated, ever-expanding pool of test questions to mitigate this issue. Key considerations include:
- For AI capability evaluations, academia has proposed many excellent methodologies for evaluating model capabilities. However, due to limited time and resources, these evaluations are often one-off and not maintained continuously. We hope to continue a series of open evaluation sets and provide third-party, black-box, and white-box live evaluations that are regularly updated.
- For Profession-Aligned evaluations: We aim to establish a mechanism to live-collect evaluation tasks from real business workflows, inviting industry professionals from various fields to co-create and maintain dynamic benchmark sets for their domains.
- Comparability over time: On the foundation of dynamic updates, we are designing capability metrics that remain horizontally comparable across iterations. This will allow us to observe not just leaderboard rankings, but also the speed of development and signals of key breakthroughs over time. Such metrics will help determine if a given model has reached the threshold for practical deployment in the market, and pinpoint when an Agent can take over an existing business process to deliver services at scale.
With these focuses, we built xbench as a new evaluation platform to break out of old paradigms and to align closely with real-world utility.
xbench Collaboration and Participation
If you’re building a foundation model or an AI Agent and want to quickly validate your product’s performance using the latest xbench evaluation sets (including access to our internal, confidential evaluation sets), we’d be glad to hear from you. We offer testing support and timely feedback, and any decisions around whether and how results are disclosed remain entirely in your hands.
We also welcome collaboration with teams developing industry-specific (vertical) AI agents, as well as domain experts and enterprises in specialized fields. We can share proven methodologies for constructing credible evaluation sets and partner with you to build and publish Profession‑Aligned xbench benchmarks tailored to your industry. In particular, we’re actively looking to work with professional experts in Human Resources (Recruiting), Marketing, Finance, Law, Sales, and Sales Ops, among other domains.
Finally, if you’re a researcher in AI evaluation with clear research ideas — especially those that require professionally curated data or long-term, evolving benchmarks — we invite you to collaborate with us. We have top-tier industry resources and connections to help bring your AI evaluation research ideas to fruition and achieve lasting impact.
For collaboration inquiries, please reach out through our contact form. And if you’d like to track progress in the meantime, you can always follow our ongoing work and explore the real-time leaderboard at xbench.org.
